HTTP es como andar en bici sin casco: funciona, pero no es lo más seguro. Es el corazón de la web, el protocolo que hace que todo funcione, pero sin la S. Esto va para vos que ya tenés una idea básica de cómo anda la web, pero querés entender un poco más sin que te abrume.
Lo que todo el mundo sabe
HTTP, o HyperText Transfer Protocol, es el idioma que usan un cliente (como tu navegador, Chrome, Firefox, o hasta una app móvil) y un servidor web para charlar. El cliente dice: “Che, dame esa página web”, y el servidor responde con el contenido, como el HTML de una página, o te tira un error tipo “404, eso no existe, amigo”. Es un diálogo simple, basado en un modelo de solicitud-respuesta.
Funciona así: el cliente abre una conexión TCP (un canal de comunicación confiable) al servidor, envía una solicitud con un método (como GET para pedir algo o POST para enviar datos), y el servidor contesta con un código de estado (200 si todo está bien, 404 si no encuentra nada, 500 si algo se rompió). La solicitud puede incluir headers, que son como notas con info extra, y a veces un cuerpo con datos. La respuesta también trae headers y, si corresponde, un cuerpo con el contenido, como una página web o un JSON.
Es súper directo, pero como no tiene cifrado, cualquiera en la red puede espiar lo que mandás o recibís.
El primer servidor web, creado por Tim Berners-Lee en 1990, era una máquina NeXT que apenas podía mostrar texto y links. Espero alguien haya corrido el Doom en eso.
Evolucion
HTTP arrancó en 1991 con la versión 0.9, que era simple, pero limitado. Solo soportaba el método GET para pedir páginas HTML, sin headers ni nada sofisticado. Era útil para compartir papers académicos, pero no mucho más.
En 1996 llegó HTTP/1.0, que agregó más métodos (como POST), headers para describir mejor el contenido (por ejemplo, qué tipo de archivo es, como texto o imagen), y códigos de estado para dar más contexto (200 OK, 404 Not Found). Pero cada solicitud abría y cerraba una conexión nueva, lo que era un garrón para servidores ocupados, porque abrir conexiones TCP todo el tiempo consume recursos.
HTTP/1.1, lanzado en 1997 y refinado en 1999, trajo mejoras grosas como conexiones persistentes (o “keep-alive”), que permitían reutilizar la misma conexión para varios pedidos, ahorrando tiempo. También sumó pipelining, para enviar múltiples solicitudes sin esperar respuestas, aunque en la práctica no se usó tanto por problemas técnicos.
Después, en 2015, apareció HTTP/2, que cambió el juego. Usó multiplexación para manejar varios pedidos y respuestas al mismo tiempo en una sola conexión, comprimió los headers para que ocupen menos espacio, y agregó “server push”, donde el servidor puede mandar recursos antes de que los pidas (como mandar el CSS junto con el HTML). HTTP/3, desde 2022, va más lejos usando QUIC, un protocolo basado en UDP que es más rápido y confiable en conexiones inestables, como cuando estás en el bondi con señal floja. Cada versión hizo la web más rápida y eficiente, como pasar de un sulky a un cohete.
Si querés meterte más, mirá la RFC 9110 de HTTP/1.1 o la docu de MDN sobre HTTP.
HTTP con S
HTTPS es HTTP con un candado. Usa TLS (Transport Layer Security, antes SSL) para encriptar todo lo que va y viene entre el cliente y el servidor. Así, si alguien intercepta el tráfico (como en un Wi-Fi público), no puede leer nada útil.
El proceso arranca cuando el cliente se conecta al puerto 443 (el estándar para HTTPS). El servidor muestra un certificado digital, emitido por una autoridad certificadora (como Let’s Encrypt), que prueba que el servidor es quien dice ser. El cliente verifica ese certificado, hacen un “handshake” usando criptografía asimétrica (como RSA) para acordar una clave simétrica, y luego todo el intercambio va cifrado. Es como pasar de mandar cartas abiertas a usar un cofre con llave.
Sin HTTPS, tus datos viajan en texto plano, listos para que los lea cualquier curioso. Desde 2014, Google baja el ranking de sitios sin HTTPS, y para 2025, más del 90% del tráfico web usa HTTPS, según datos de telemetría.
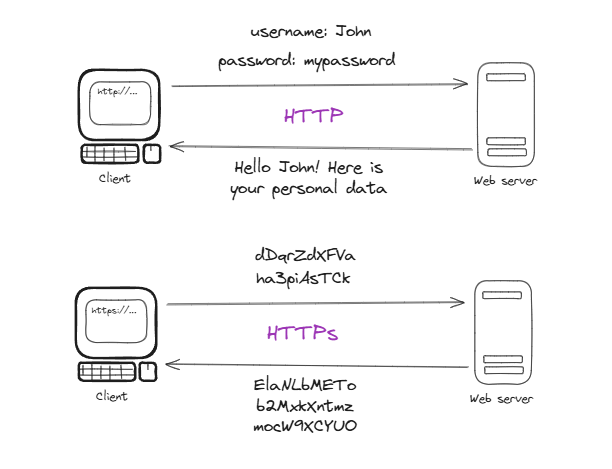
HTTP puro hoy en día es como gritar tu contraseña en una plaza, tarde o temprano alguien te va a escuchar.
Las tres partes de solicitud y respuesta
Un mensaje HTTP, ya sea solicitud o respuesta, tiene tres partes: la línea inicial, los headers y el cuerpo. Vamos por partes.
- Línea inicial: En una solicitud, dice qué querés hacer (método, como GET o POST), qué recurso (la URL, como /index.html) y la versión de HTTP (como HTTP/1.1). En una respuesta, incluye el código de estado (200 OK, 404 Not Found) y la versión. Es como el título de la conversación.
- Headers: Son pares clave-valor que dan contexto. Por ejemplo, en una solicitud, el header Host indica a qué dominio va dirigida (clave en servidores que alojan varios sitios). User-Agent dice qué navegador o cliente estás usando. Content-Type especifica el formato del cuerpo (como text/html o application/json). En respuestas, Server te cuenta qué software usa el servidor (como Apache o Nginx), y Cache-Control indica si el navegador puede guardar el recurso y por cuánto tiempo (ejemplo: max-age=3600 para una hora). Particularmente, mi encabezado HTTP favorito es Location, usado en redirecciones (como cuando te mandan de /old a /new). ¿Qué? ¿No todos tienen un encabezado HTTP favorito?
- Cuerpo: Es el contenido real, como el HTML de una página, un JSON con datos, o una imagen. En un GET, el cuerpo de la solicitud suele estar vacío, pero en un POST puede llevar datos de un formulario. En la respuesta, el cuerpo es lo que ves en pantalla o procesás en tu app.
En HTTP/1.0, no había soporte para enviar cuerpos en pedazos (chunked transfer), así que si querías mandar algo grande, como un video en streaming, tenías que calcular el tamaño total antes, lo que era un dolor de cabeza.
Y listo, no te quemo más la cabeza. Si querés profundizar, hay un montón de recursos online para seguir investigando.
Chau.