HTTP is like riding a bike without a helmet: it works, but it’s not the safest. It’s the backbone of the web, the protocol that keeps everything running, but without the S. This is for you who already have a basic idea of how the web works but want to understand a bit more without getting overwhelmed.
What Everyone Knows
HTTP, or HyperText Transfer Protocol, is the language that a client (like your browse Chrome, Firefox, or even a mobile app) and a web server use to communicate. The client says, “Hey, give me that webpage,” and the server responds with the content, like the HTML of a page, or throws an error like “404, that doesn’t exist, buddy.” It’s a simple request-response model.
Here’s how it works: the client opens a TCP connection (a reliable communication channel) to the server, sends a request with a method (like GET to fetch something or POST to send data), and the server replies with a status code (200 for success, 404 for not found, 500 if something broke). The request can include headers, which are like notes with extra info, and sometimes a body with data. The response also comes with headers and, if needed, a body with the content, like a webpage or JSON data.
It’s super straightforward, but since it lacks encryption, anyone on the network can snoop on what you send or receive.
The first web server, created by Tim Berners-Lee in 1990, was a NeXT machine that could barely handle text and links. Hope someone ran Doom on that thing.
Evolution
HTTP started in 1991 with version 0.9, which was simple but limited. It only supported the GET method for fetching HTML pages, with no headers or anything fancy. It was useful for sharing academic papers, but not much else.
In 1996, HTTP/1.0 arrived, adding more methods (like POST), headers to better describe the content (e.g., what type of file it is, like text or image), and status codes for more context (200 OK, 404 Not Found). But each request opened and closed a new connection, which was a pain for busy servers since establishing TCP connections eats up resources.
HTTP/1.1, launched in 1997 and refined in 1999, brought major improvements like persistent connections (aka “keep-alive”), which allowed reusing the same connection for multiple requests, saving time. It also added pipelining to send multiple requests without waiting for responses, though in practice, it wasn’t widely used due to technical issues.
Then, in 2015, HTTP/2 changed the game. It used multiplexing to handle multiple requests and responses simultaneously over a single connection, compressed headers to take up less space, and introduced “server push,” where the server can send resources (like CSS) before you ask for them. HTTP/3, since 2022, goes further with QUIC, a UDP based protocol that’s faster and more reliable on unstable connections, like when you’re on a bus with spotty signal. Each version made the web faster and more efficient, like going from a horse cart to a rocket.
If you want to dive deeper, check out RFC 9110 for HTTP/1.1 or MDN’s HTTP docs.
HTTP with S
HTTPS is HTTP with a lock. It uses TLS (Transport Layer Security, formerly SSL) to encrypt everything going back and forth between the client and server. So, if someone intercepts the traffic (like on public Wi-Fi), they can’t read anything useful.
It starts when the client connects to port 443 (the standard for HTTPS). The server presents a digital certificate, issued by a certificate authority (like Let’s Encrypt), proving it’s who it claims to be. The client verifies the certificate, they do a “handshake” using asymmetric cryptography (like RSA) to agree on a symmetric key, and then all communication is encrypted. It’s like moving from sending open letters to using a locked chest.
Without HTTPS, your data travels in plain text, ready for any nosy person to read. Since 2014, Google has penalized non-HTTPS sites in search rankings, and by 2025, over 90% of web traffic uses HTTPS, according to telemetry data.
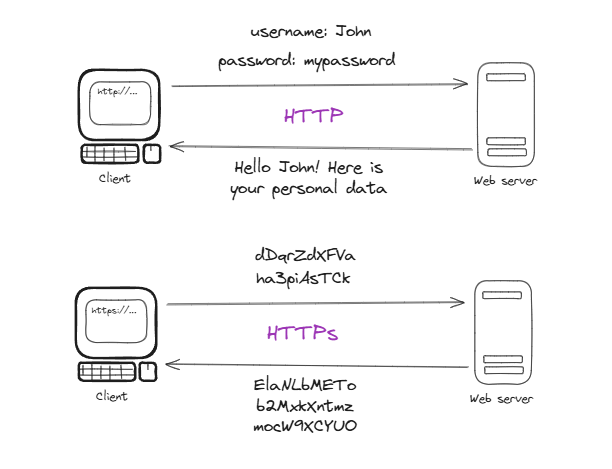
Plain HTTP today is like shouting your password in a crowded square—sooner or later, someone’s going to hear it.
The Three Parts of Request and Response
An HTTP message, whether a request or response, has three parts: the start line, headers, and body. Let’s break it down.
- Start Line: In a request, it says what you want to do (method, like GET or POST), what resource (the URL, like /index.html), and the HTTP version (like HTTP/1.1). In a response, it includes the HTTP version, status code (200 OK, 404 Not Found), and a brief description. It’s like the title of the conversation.
- Headers: These are key-value pairs that provide context. For example, in a request, the Host header specifies which domain you’re targeting (crucial for servers hosting multiple sites). User-Agent identifies your browser or client. Content-Type defines the body’s format (like text/html or application/json). In responses, Server reveals the server’s software (like Apache or Nginx), and Cache-Control tells the browser if it can cache the resource and for how long (e.g., max-age=3600 for an hour). My personal favorite HTTP header is Location, used for redirects (like sending you from /old to /new). What? Don’t you have a favorite HTTP header?
- Body: This is the actual content, like a page’s HTML, JSON data, or an image. GET requests usually have an empty body, but POST requests might include form data. In responses, the body is what you see onscreen or process in your app.
In HTTP/1.0, there was no support for sending bodies in chunks (chunked transfer), so for big stuff like streaming video, you had to calculate the total size upfront, which was a headache.
That’s it, no more brain fry. If you want to dig deeper, there’s a ton of resources online to keep exploring.
Cheers.